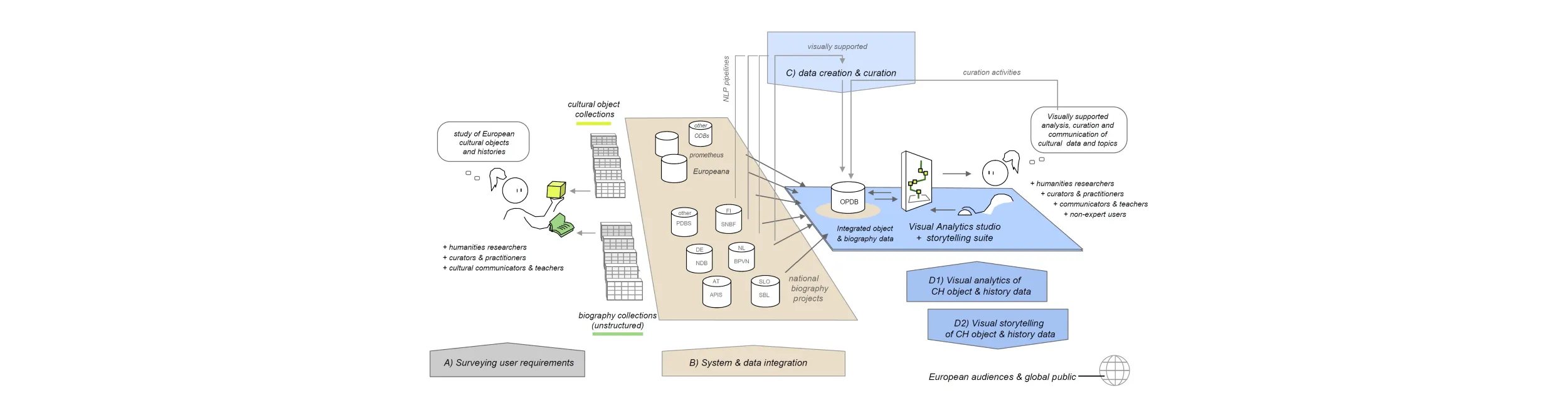
System Architecture
The InTaVia project aims to address major research challenges and bridge the semantic gap between large object databases, biography databases, and present-day users, as outlined in Figure 1. The project will conduct research and development across multiple domains (from digital humanities, natural language processing (NLP), semantic web technologies, visual analytics, human-computer interaction, to historiographical research). Starting from the rich technology stack present in the consortium, we will develop new concepts and ideas, and bring them to their prototypical implementation and evaluation (technology readyness level 5). To organize this endeavor, the consortium will rely on extensive experience with related research activities. Following a user-centered approach to system development, the intended target groups (A) will provide essential input for the system's requirement specifications. These requirements will provide the criteria for decisions on system and data integration (B), for the advancement of text mining technologies (C), and for the development of a visual analytics environment for the analysis, curation, and communication of cultural heritage object and historiographical data (D). We describe each component below.
Figure 1. Overview of the InTaVia system, based on the survey of user requirements (A), integrating multiple object database and biography database projects (B), and enabling further data curation and creation (C) within an advanced visual analytics and storytelling environment (D).
Historiographic research questions and user requirements
The cultural and intellectual history of every European country has been profoundly shaped by the emergence of ideas, objects, arts, and technologies—and by their transnational movement and diffusion over time. However, this does not become apparent in decontextualized digital object databases and nationally organized data infrastructures. InTaVia will build up a transnational object-biography- database and platform to work with in/tangible cultural assets and will thereby help to answer new types of synoptic research questions:
- across hitherto separated types of cultural assets (tangible objects and intangible (hi)stories): How can tangible assets be represented, analyzed and communicated in the context of intangible cultural (hi)stories? How are individual objects (or selections) situated in artists' oeuvres? What were the productive creative phases and developments of individuals? How do they compare by professions or by periods?
- across national boundaries: How are individual objects or collections situated in trans/national corpora? How can we compare different corpora in space and time (g.corpora created by different art movements, by different professions, by different countries)? How did individual lifepaths influence each other—e.g. via transnational migration and exchange—and how did their “composite (hi)stories” (of groups, organizations or regions) shape different macrohistorical dynamics?
- across scales of aggregation (from individual entities to socio-cultural composites): How do the object-oriented (hi)stories of individuals vs. composite entities look like (groups, organizations, cities)? What were their creative and cultural dynamics? How were they affected by parallel historical developments?
InTaVia will not only support analytical research activities, but also facilitate new practices of cultural data creation, curation, and communication. By collecting and organizing relevant practices and research questions, we will derive and document associated needs and requirements of different user groups to guide our developments.
With specific regard to more complex (i.e. hybrid, combinatorial, comparative) research, curation and communication practices, users require novel technologies and options to investigate cultural data across the tangible/intangible divide, across national (data) boundaries, and across various scales of data aggregation. To deal with such complex questions, the InTaVia project implements a user-centered development process, which starts with collecting and documenting exemplary questions and associated user practices. The results will be transferred to the consortial working groups and collectively evaluated in order to derive design and development requirements from a data, user and task-analytical perspective (Miksch & Aigner, 2014).
System and data integration
To enable the outlined type of complex research—and to support related data curation, communication and promotion practices—InTaVia will draw together a variety of data resources and integrate them with a novel system architecture. As a consequence, InTaVia will help to work with cultural data across well-known (infra)structural fractures, including established data separations due to 1) types of cultural assets (tangible and intangible), 2) national boundaries, and 3) ranges of scale (from individual entities to large composites).
On the integration of tangible and intangible data
In line with the work program, InTaVia will interlink and consolidate data on tangible and intangible assets. For that end, we will establish an integrated object-biography-database system architecture—and pioneer an integrated data model building on a transnational prosopographical data model and will integrate tangible cultural objects. Though the data models of object and biography databases have some common sources such as CIDOC CRM and technically also allow their mutual inclusion (e.g. BioCRM by Tuominen et al., 2017 includes primitives for objects), they put emphasis on different aspects. For object databases, the Europeana Data Model EDM is widely accepted, but current biography data models vary to a greater extent (Fokkens et al., 2016). Therefore, a novel integrative data model is required, which is able to link both object databases and biography databases.
In general, there is little prior research on combining intangible and tangible heritage data. An exception is the Relational Search application view of the BiographySampo system (Hyvönen & Rantala, 2019). Here collection data about paintings (from the National Gallery of Finland), publication data (from the LOD version of the National Bibliography of Finland) and the Booksampo semantic portal (of Public Libraries in Finland), as well as epistolary letter data have been interlinked with biographies in order to enable serendipitous knowledge discovery in relational knowledge graph search with the goal to find and explain interesting and surprising semantic connections between concepts, such as persons and places. InTaVia will apply and further develop experiences, software, and data from this case study in a larger context.
During recent years knowledge graph platforms such as WissKI (http://wiss-ki.eu/), ResearchSpace (https://www.researchspace.org/), Wikibase (https://wikiba.se/) and the Sampo system (Hyvönen, 2020b) have dramatically decreased the development burden for semantic web applications. The InTaVia consortium brings together knowledge on at least three of these systems (ResearchSpace, Wikibase, Sampo). While we will carefully evaluate these systems, the Finnish Sampo framework (Hyvönen, 2020) appears as a promising option. It creates a shared ontology infrastructure, uses a business model based on open data sharing and FAIR principles, and a two-step filter-analyze loop in the UI that actually originates from basic prosopographical research patterns. For this model, also an infrastructure and publishing platform LDF.fi (http://ldf.fi) based on the “7-star” Linked Data model is freely available. The model also includes the Sampo-UI framework for developing user interfaces, based on the latest development tools and libraries, such as React, Redux, NodeJS, Express, Cytoscape, NetworkX, Google Charts, and various GIS-tools for maps, including historical ones. This framework facilitates modular user interface development of separate applications in a distributed environment, which is an important feature for a project such as InTaVia. The Sampo model has already been used and tested in several semantic portals and LOD services that are in use with several thousand end users and large SPARQL endpoints of millions of data instances.
On the transnational aggregation and integration of biography databases
To aggregate intangible data on European cultural (hi)stories, the InTaVia project team brings together four national biography database projects associated to its working groups (FI, NL, AT, SI)—and will include open biography databases from eight further countries (AU, DE, CH, CZ, BE, HR, HU, UK)—to harmonize their structured inventories. This requires both technical solutions for combining data and retrieving it via an API for further processing and analysis and interpretation solutions for providing meaningful links between data. Currently the data models as well as the format of the twelve biography databases differ substantially: e.g. event-based vs. relation-based data models and inline vs. stand-off annotation. To release the full potential of the consortium's collective corpus (250.000+ biographies), we need to assure that the data is available in a harmonized common data model to allow for their integration, easy statistical analyses and visualizations. The InTaVia project will develop novel interoperability standards to integrate various resources into one common database. Firstly, the data models will be converted to RDF, staying as close to the original model as possible, secondly, relation-based data models will be converted to event-based representations by introducing event-nodes and, thirdly, the individual data models will be translated to a common data model (Fokkens et al., 2016). In detail, we will (a) create a common data model / ontology; (b) harmonize local vocabularies employing existing standards such as Simple Knowledge Organization System (SKOS, for feasibility reasons, we focus on top-level concepts); (c) create a common knowledge base using a) and b); (d) develop and employ plugins to (semi)automatically select, link and merge objects (e.g. the same person depicted by two different URIs) in the common knowledge base; and (e) provide means for manual review and curation of these automatic processes.
Practitioners without knowledge of the underlying technical procedures should be able to quickly assess the quality of the data and metadata at their hands. Data within an object-biography-database knowledge base are certainly of varying quality, information density, and from different origins, therefore data heterogeneity will have to be addressed. To cope with these challenges, we will use ontologies such as PROV-DM (Belhajjame et al., 2013) for modeling the data's provenance (original source as well as processes applied to the data) building on the earlier work by Ockeloen et al. (2013). It allows researchers to unveil the provenance of the data and reproduce—if needed—every decision taken by automatic tools (e.g. the NLP models and settings used for text mining, see section C). To foster a more intuitive understanding, data quality indicators (such as confidence scores) will be prominently featured in the visualizations and will support manual curation and analysis of the data.
On the aggregation of individual biographies to biographical composites
InTaVia aims to contextualize tangible cultural assets (e.g., historical images, texts, musical manuscripts, films, buildings, or technological artifacts) within different constellations of intangible (hi)stories, which will range from (parts of) individual biographies to the histories of large socio-cultural composites (such as groups, organizations, and regions). While the visually supported aggregation—and subsequent analysis and communication—of such composites will establish new biographical standards, the further integration of related cultural objects will be of specific value (e.g. in art history) and will extend the scope of research in these fields. For that matter, the InTaVia project will provide the means to select and synthesize biographical composites according to different aggregation criteria, such as shared group or family affiliations, membership in organizations, or relation to geographic regions. For instance, users can investigate which artists may have influenced each other by comparing who studied or worked at a specific location in a given time.
We will also explore strategies to support serendipitous knowledge discovery in object-biography-databases (Hyvönen, 2020a), to foster “happy and unexpected discoveries by accident” (Thudt et al., 2012, p. 2), and to generate new research questions and lines of inquiry. For that matter, we will explore how we can create novel relations by utilizing AI-driven, algorithmic matching and linking strategies to suggest connections of hitherto unconnected entities in our knowledge base, using different machine learning and reasoning engines, for the sake of a better linkage of the database (Hyvönen, 2020a). Related research intertwines techniques of creative problem solving (Zwicky, 1969), computational creativity (Boden, 2009), and explainable AI to make the computational reasoning transparent to end users, which is particularly important in source-critical digital humanities research.
Mining and curation of biographical and other historiographical text
To resituate tangible cultural assets in relevant cultural and historical constellations, InTaVia will tap into the rich historiographical repositories of national biography database projects. These projects emerged from the semantic processing of national biographical lexica and thus provide a wealth of semi-structured data for thousands of individual biographies—and for higher-level aggregation to composite (hi)stories. We consider this data to provide a functional core, and we aim for its continuous growth in terms of number, variety, and especially quality of entries. Therefore, technologies for further data creation from various sources and curation will be of the essence. These will enable InTaVia users to extract new structured data from unstructured texts and to curate (i.e. to correct, refine and enrich) existing entries by manual and (semi)automated means.
Text mining for dynamic language analysis: To this end, we will provide both NLP models specialized in mining English, Dutch, Finnish, German and Slovene biographical text (WP4) (1). These models will extract information and represent it in the harmonized object-biography-data model (WP3). We furthermore provide access to state-of-the-art generic NLP models in an interactive environment so that users can provide input for adapting them to other historiographic domains (2). We include a language change support suite that specifically targets challenges related to language change (3).
Interoperable multilingual models for mining biographical text
InTaVia aims to make more information from historiographical resources available to users by applying text mining models that extract information and represent it as structured data. We provide both specialized models for biographical text as well as more generic models which can be adapted for various text types (see (ii) and (iii)). We focus on biographical information that allows users to connect people to related objects, other people, but also to specific time periods and art movements. Previous work on extracting person information often uses online data such as Wikipedia (e.g. Gonzales-Dios et al., 2015; Menini et al., 2017; Yao & Van Durme, 2014). These approaches are not designed to deal with the idiosyncrasies of biographical data (in particular; old language use and source specific abbreviations). Specialized approaches have been applied by Bonch-Osmolovskaya and Kolbasov (2015) for Russian, Fokkens et al. (2018) for Dutch with similar pipelines for English, Spanish and Italian (Vossen et al., 2016), for Finnish (Tamper et al., 2018) and German (e.g. Lejtovicz & Dorn, 2017). InTaVia will build upon these technologies for Dutch, Finnish, German and English sources. For Slovene, we focus on possibilities offered by standard NLP technologies (Ljubešic et al., 2016). Interoperability will be ensured through the output representation in RDF, where the content is compatible with the harmonized object-biography-data model. The content will be embedded in the Grounded Representation and Source Perspective framework (GRaSP, Fokkens et al. 2017), which allows for representing alternative views, provides direct links to the original text and uses the PROV-DM for representing the technical provenance chain.
A dynamic text mining environment for (a wider range of) historiographical texts
To further advance the quality of the NLP models and to make our technologies more flexible for new types of text (e.g. news articles from news archives maintained by the consortium or associated organisations), we will develop a dynamic environment, where users can upload data and interact with different NLP models. We support both retraining and integrating structured domain specific knowledge. Retraining allows us to apply state-of-the-art language models to biographical data as well as facilitate text mining for other historiographical domains, such as object biographies—or accounts on the history of families and groups, on the histories of organizations and institutions, and on the histories of regional entities.
The specialized models mentioned in (i) provide a strong starting point for analyzing biographical data, but most of them do not exploit the full potential of the latest advances in NLP. Deep learning has pushed the state-of-the-art for most NLP tasks. One of the challenges of using (deep) neural networks is that they need massive amounts of data, typically not available for highly specialized domains. NLP deals with this challenge by means of generic language models that capture linguistic properties by being trained on so-called auxiliary tasks. Word embeddings that are created by predicting a word given its context (word2vec, Mikolov et al., 2014) are an example of such a language model. These embeddings can be used to represent words in machine learning setups. The latest generic models, notably BERT (Devlin et al. 2019), are deep neural networks themselves and can be used in various tasks through retraining. Though word2vec embeddings have been used successfully to increase result for mining historiographical data (e.g. Schulz & Kuhn, 2016), and BERT can be adapted to a new domain through retraining (Han & Eisenstein, 2019), it is unclear whether this procedure is possible with the limited data volumes typical for historiographic resources. InTaVia provides an excellent environment to dive deeper into the possibilities and limitations of such models: The combination of structured data and text can provide more training data than is typically available for cultural heritage data and the preprocessing tools we have in place allow us to compare the impact of cleaning data versus retraining. Moreover, we address languages with richer morphological structure than English (notably Slovene and Finnish) for which insights in the impact of sublexical structures are highly relevant (e.g. as done in (probabilistic) FastText (Athiwaratkun et al., 2018)).
We use an active learning approach to facilitate this procedure (e.g. Siddhant & Lipton, 2018), where the machine provides users with automatically annotated examples and asks for feedback. The correction or confirmation of the user is used to improve the system. For optimizing the process, borderline decisions can be presented to users. In our case, we also ask users to provide parameters of their overall research questions and indicate whether the models should prioritize high precision or high recall. This way users are stimulated to evaluate sufficient data to measure the impact of erroneous automatic analysis on their research, in particular, when such analyses introduce biases (Fokkens et al., 2014). This process is supported by a visual analytic environment (see Sec. 1.3.1.4, Component V).
A language change support suite
Historiographical data often contains sources from various time periods. As such, language change can make these texts challenging for both humans and machines. We make use of digitized expert knowledge on sense shift and spelling variations developed over the last decades as well as the latest NLP methods. Character embeddings, e.g., have been used successfully for OCR corrections and for detecting spelling variations (Athiwaratkun et al., 2018; Hämäläinen & Hengchen, 2019). We offer these methods next to character-based statistical machine translation, used successfully for Slovene (Scherrer & Erjavec, 2013). Several studies have used word embeddings created from diachronic corpora to detect changes in word sense automatically (Hamilton et al., 2016; Mitra et al., 2014). Though some report high accuracy, these results are typically based on words known to have changed radically (e.g. gay, cell). Due to a lack of larger, more balanced evaluation data, the actual quality of their outcome for more general cases is currently unknown (e.g. Kutuzov et al., 2018). Moreover, the size of the corpora is often limited and algorithms to create word embeddings are influenced by random factors (Hellrich & Hahn, 2016). Several researchers have provided guidelines to verify the robustness of results automatically and through expert knowledge (e.g. Dubossarsky et al., 2017; Sommerauer & Fokkens, 2019).
We make use of the environment described in (ii) to enable users to make use of the latest methods of detecting change (including methods specialized on small corpora, e.g. Herbelot & Baroni, 2017), run automatic validation checks (e.g. Bloem et al., 2019) and provide input for validation themselves. The environment also allows them to provide expert knowledge beforehand to be used for preprocessing (e.g. replacing words with more modern counterparts to improve similarity with modern corpora). This procedure can be applied in a bootstrapping fashion, where users approve machine suggested changes, which are used for preprocessing in a next detection round. The biographical data we start from also contain entries written in different time periods, between which language use changed. This includes (linked) entries on the same person written in different times which allows us to automatically create points of alignment, since the same names and topics are likely to be mentioned in these sources. Together with user feedback, this setup leads to a synergetic approach where humanities scholars can use the latest NLP technologies and computational linguistics receive much needed evaluation data that provides known variations and change.
Data curation (manually & assisted): Automatically extracted data from biographical lexicons and other historical texts are known to be of relatively modest data quality: relatively few data points, uncertain data points—and they are usually 'static', i.e. they remain stable after their automated extraction. InTaVia aims to overcome this state of affairs by deliberately supporting (distributed and ongoing) activities of data curation.
This will enable different users (such as scholars, cultural heritage practitioners or teachers) to work with existing entries (e.g. for a specific individual or a composite)—but also to add missing events, to disambiguate, delete or correct faulty entries, or to suggest different interpretations (e.g. for contested or controversial figures and accounts). These activities will be supported by a text-based editor for structured data, data visualizations within the visual analytics studio (see Figure 2), and plugins using algorithmic and/or machine learning approaches for (semi)automated editing workflows. Visual analytics approaches can support these machine-assisted workflows in several ways: Firstly, confidence values can be visually communicated to provide an initial indication of data (un)certainty. This will help data curators to focus on specific cases of interest, e.g. extractions with low confidence. Secondly, visual support for comparing the outputs of multiple plugins will be provided to fine-tune extraction tasks and increase overall extraction quality. And thirdly, interactive means for visual inspection of texts—and data extracted from them—will be provided on different levels of abstraction to support users in grasping the context of extractions quickly. The latter aims to increase efficiency and effectiveness of (semi-)automated data curation. InTaVia will explore possibilities for storing any changes made by scripts and researchers in an annotation layer without touching the original data (e.g. by using PROV-DM to record the provenance of the data).
Visual analysis and communication of object & biography collection data
To facilitate the analysis and interpretation of in/tangible cultural asset collections from multiple points of view—but also to support data selection, aggregation, exploration, creation and curation—the InTaVia project will utilize and develop a combination of advanced visual analytics technologies. These will be synthesized and functionally integrated within a visual analytics studio (WP5) with a focus on data analysis and data management functions for scholars and cultural heritage practitioners. To complement this component—and to ensure accessible and attractive output for a wide range of non-expert audiences—a visual storytelling suite will be developed, to transform data about in/tangible (hi)stories into compelling narrative visualizations (WP6).
Visual analytics studio (D1): Visual analytics technologies bring the capabilities of humans and computers together, to support understanding, sensemaking and decision making of analysts in face of massive, heterogeneous, dynamic, and ambiguous data. With growing collections of digital information in cultural heritage and digital humanities research, visual analytics have become an important factor in these fields as well.
The InTaVia project will develop a multifunctional visualization component (referred to as visual analytics studio) to apply novel and state-of-the-art visualization methods to the established object-biography-database. The visual analytics studio will integrate five functional components to enable the visual analysis of object-biography-data:
-
Offering multiple views on object and historiographical data: Visualizations offer effective means to make cultural information visible and explorable on various scales (overview – detail) in various selections (individual – group) and from various perspectives. Multiple approaches to visually analyze object or biography data have been introduced, putting emphasis either on geographical, relational, categorical or temporal data dimensions (see Fig. 2, top right). We will implement a robust selection of multiple views, to utilize the advantage of such a design “to maximise insight, balance the strengths and weaknesses of individual views, and avoid misinterpretation” (Kerracher et al., 2014, p.3). As we consider the temporal dimension of biography data and object collections to be of crucial relevance, we will also provide multiple temporal layouts (such as layer juxtaposition, layer superimposition, animation, and space-time cube representations, see Fig. 2, center). As such, we can “allow the user to select and switch between the most appropriate representations for the data and task at hand” (ibid.).
-
Integrated visual analytics studio with coordinated views: The visual analytics studio will combine these multiple views into an interface with coordinated views (Baldonado et al., 2000). This will enable users to explore object and biography data selections (objects or collections and persons or prosopographical composites) from multiple analytical perspectives (e.g. in their geographical, relational, categorical, or temporal contexts) in parallel. To cope with the risk of split attention (Cockburn et al., 2008), we will focus on techniques to support the integration of insights and information from multiple views (Schreder et al., 2016). Among them we count the consistent encoding of data dimensions, coordinated interaction techniques (e.g. linking and brushing), seamless layout and canvas transitions, and the use of space-time cube representations (Windhager et al., 2017a; 2017b; 2020).
-
Visual query/filtering language: The coordinated views approach will be integrated with an interactive visual querying and filtering mechanism (Young & Shneiderman, 1993) and take the latest research on visual query mechanisms for event-based information into account (Krüger et al., 2020) to orchestrate the different backend systems into one coherent visual frontend. The seamless integration of the visual query mechanism will help users define their data set of interest as well as widen or change it on demand during analysis (Koch et al., 2011). A visually supported graph traversal mechanism might be adopted to query in particular relational data (Amor-Amorós et al., 2016). The filter/query mechanism will help to keep track of visual-analytical steps, to share results with collaborators, and to make experiments reproducible by capturing the analytic provenance of researchers' findings. InTaVia will incorporate data provenance of the backend system and help to make data heritage—as well as analysis steps taken later on—as transparent to users as possible.
-
Representing data quality and provenance InTaVia will deal with uncertain historical information on various levels, e.g., inexact temporal or geographical information, contradicting sources, or data that is completely missing. Additional uncertainty is introduced through automatic processing of language resources, which is an inevitable precondition to making large biographical collections available. The consortium will leverage taxonomies of dirty data (e.g., Gschwandtner et al., 2012) and will develop suitable visual representations of uncertainty supporting users with an interpretation of the provided information (Windhager et al., 2019b). To enable access to original sources (e.g. for disambiguation), the visual analytics studio will offer direct access to original data and text sources on demand, enabling researchers to switch from 'distant' to 'close' reading interactively (Jänicke et al., 2015). Showing the uncertainties that were involved to achieve a certain information together with data provenance information is an important factor to make research results transparent (Bors et al., 2015, 2016) and to prevent scholars from drawing conclusions that might not stand up to scrutiny, but still have value as a working hypothesis (Franke et al., 2020). It will also help to guide manual curation effort to data that requires the most attention.
-
Visual support for transparent data creation and curation: Another component of the visual analytics studio will visually support document annotation and text mining, to help users without NLP background knowledge understand annotation differences and possible problems from automatic processing quickly. As opposed to more general-purpose annotation approaches such as WebAnno (de Castilho et al., 2016) and CATMA (Bögel et al., 2015), our approach will focus on comparison and refinement of annotation and processing runs (Baumann et al., 2020). Research on visual support of text mining (Heimerl et al., 2012; Koch et al., 2014; Lord et al., 2006; Zhao et al., 2012) has been greatly increased in recent years. Still, InTaVia would be among the first to design visual approaches for assessing the quality of text mining that help to cope with the inevitable issues of automated mining.
Visual storytelling suite (D2): The InTaVia platform will complement the visual analytics studio with a visual storytelling suite, to create guided narrative visualizations for public audiences. Whereas the visual analytics studio provides analysts with open views on the structures, distributions, relations and patterns within complex data for exploration and analysis, storytelling visualizations guide the user's perception with linear reading and messaging strategies (“author driven” approach, Segel & Heer, 2010). Among the many advantages of such visual stories are increased options for messaging, causal connectivity, dramatic structure, narrative engagement—and thus increased accessibility and memorability of complex content (Mayr & Windhager, 2018; Riche et al., 2018). Despite well-known benefits, visual storytelling has rarely been used to effectively narrate complex object collections (Windhager et al., 2019a, p.2324)—and we are not aware of narrative visualization approaches to represent biography data, even though the sequential data structure of historiographical data practically calls for narrative designs (Mayr & Windhager, 2018).
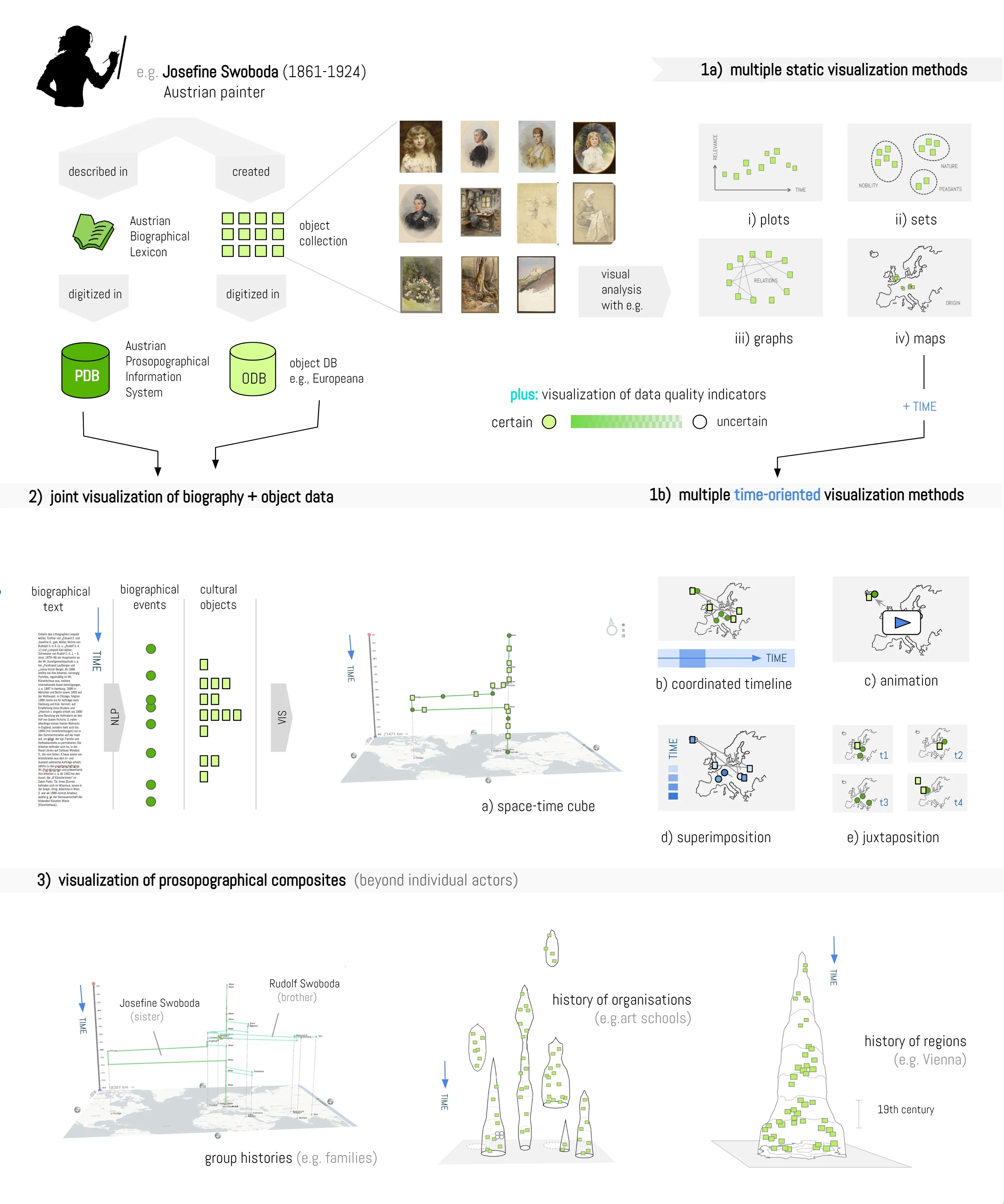
Figure 2. Overview of visualization options for object data (top right), for biography and object data (center), and for biographical composites beyond individual actors (bottom).
To fill this research & development gap, we will (i) draw together examples and best practices of narrative visualizations from various application fields with a survey study, to document visual storytelling options for in/tangible cultural (hi)stories. Informed by this study, we will (ii) develop and test multiple narrative visualization designs with specific regard to the requirements of expected audiences and the affordances of InTaVia data. Based on the evaluation results, we will (iii) implement prototypes for the most effective narrative visualizations in a storytelling suite, which will enable InTaVia users to create compelling data-based narrative content about object-biography (hi)stories for public audiences while preserving the direct link to the related data-sources and therewith making the scientific basis of the stories transparent. In addition, (iv) we will ensure the adaptation of narrative visualizations for mobile devices and explore various strategies to maximize user experience and user engagement, explore gamification options, and use extended reality.
With the proposed combination of a visual analytics studio and a connected visual storytelling suite, InTaVia aims to decidedly go beyond the current state of the art and utilize novel visualization techniques to explore European in/tangible cultural histories on different levels of abstraction.